Indexing, Slicing and Subsetting DataFrames in Python
Overview
Teaching: 30 min
Exercises: 30 minQuestions
How can I access specific data within my data set?
How can Python and Pandas help me to analyse my data?
Objectives
Describe what 0-based indexing is.
Manipulate and extract data using column headings and index locations.
Employ slicing to select sets of data from a DataFrame.
Employ label and integer-based indexing to select ranges of data in a dataframe.
Reassign values within subsets of a DataFrame.
Create a copy of a DataFrame.
Query / select a subset of data using a set of criteria using the following operators:
=,!=,>,<,>=,<=.Locate subsets of data using masks.
Describe BOOLEAN objects in Python and manipulate data using BOOLEANs.
In the first episode of this lesson, we read a CSV file into a pandas’ DataFrame. We learned how to:
- save a DataFrame to a named object,
- perform basic math on data,
- calculate summary statistics, and
- create plots based on the data we loaded into pandas.
In this lesson, we will explore ways to access different parts of the data using:
- indexing,
- slicing, and
- subsetting.
Loading our data
We will continue to use the surveys dataset that we worked with in the last episode. Let’s reopen and read in the data again:
# Make sure pandas is loaded
import pandas as pd
# Read in the survey CSV
surveys_df = pd.read_csv("data/surveys.csv")
Indexing and Slicing in Python
We often want to work with subsets of a DataFrame object. There are different ways to accomplish this including: using labels (column headings), numeric ranges, or specific x,y index locations.
Selecting data using Labels (Column Headings)
We use square brackets [] to select a subset of a Python object. For example,
we can select all data from a column named species_id from the surveys_df
DataFrame by name. There are two ways to do this:
# Select a 'subset' of the data using the column name
# TIP: use the .head() method we saw earlier to make output shorter
surveys_df['species_id']
We can also create a new object that contains only the data within the
species_id column as follows:
# Creates an object, surveys_species, that only contains the `species_id` column
surveys_species = surveys_df['species_id']
We can pass a list of column names too, as an index to select columns in that order. This is useful when we need to reorganize our data.
NOTE: If a column name is not contained in the DataFrame, an exception (error) will be raised.
# Select the species and plot columns from the DataFrame
surveys_df[['species_id', 'plot_id']]
# What happens when you flip the order?
surveys_df[['plot_id', 'species_id']]
# What happens if you ask for a column that doesn't exist?
surveys_df['speciess']
Python tells us what type of error it is in the traceback, at the bottom it says
KeyError: 'speciess' which means that speciess is not a valid column name (nor a valid key in
the related Python data type dictionary).
Extracting Range based Subsets: Slicing
Reminder
Python uses 0-based indexing.
Let’s remind ourselves that Python uses 0-based
indexing. This means that the first element in an object is located at position
0. This is different from other tools like R and Matlab that index elements
within objects starting at 1.
# Create a list of numbers:
a = [1, 2, 3, 4, 5]
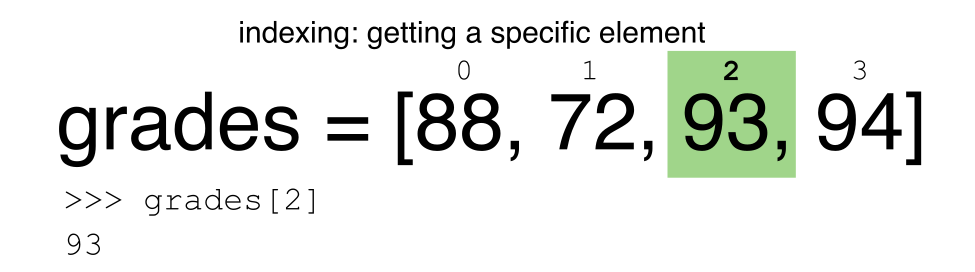
Challenge - Extracting data
What value does the code below return?
a[0]How about this:
a[5]In the example above, calling
a[5]returns an error. Why is that?What about?
a[len(a)]
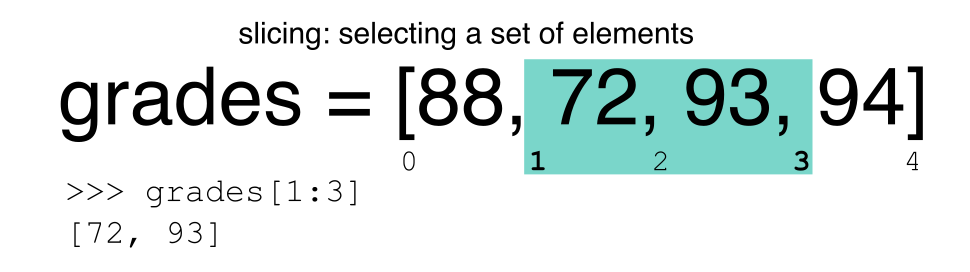
Slicing Subsets of Rows in Python
Slicing using the [] operator selects a set of rows and/or columns from a
DataFrame. To slice out a set of rows, you use the following syntax:
data[start:stop]. When slicing in pandas the start bound is included in the
output. The stop bound is one step BEYOND the row you want to select. So if you
want to select rows 0, 1 and 2 your code would look like this:
# Select rows 0, 1, 2 (row 3 is not selected)
surveys_df[0:3]
The stop bound in Python is different from what you might be used to in languages like Matlab and R.
# Select the first 5 rows (rows 0, 1, 2, 3, 4)
surveys_df[:5]
# Select the last element in the list
# (the slice starts at the last element, and ends at the end of the list)
surveys_df[-1:]
We can also reassign values within subsets of our DataFrame.
But before we do that, let’s look at the difference between the concept of copying objects and the concept of referencing objects in Python.
Copying Objects vs Referencing Objects in Python
Let’s start with an example:
# Using the 'copy() method'
true_copy_surveys_df = surveys_df.copy()
# Using the '=' operator
ref_surveys_df = surveys_df
You might think that the code ref_surveys_df = surveys_df creates a fresh
distinct copy of the surveys_df DataFrame object. However, using the =
operator in the simple statement y = x does not create a copy of our
DataFrame. Instead, y = x creates a new variable y that references the
same object that x refers to. To state this another way, there is only
one object (the DataFrame), and both x and y refer to it.
In contrast, the copy() method for a DataFrame creates a true copy of the
DataFrame.
Let’s look at what happens when we reassign the values within a subset of the DataFrame that references another DataFrame object:
# Assign the value `0` to the first three rows of data in the DataFrame
ref_surveys_df[0:3] = 0
Let’s try the following code:
# ref_surveys_df was created using the '=' operator
ref_surveys_df.head()
# surveys_df is the original dataframe
surveys_df.head()
What is the difference between these two dataframes?
When we assigned the first 3 columns the value of 0 using the
ref_surveys_df DataFrame, the surveys_df DataFrame is modified too.
Remember we created the reference ref_survey_df object above when we did
ref_survey_df = surveys_df. Remember surveys_df and ref_surveys_df
refer to the same exact DataFrame object. If either one changes the object,
the other will see the same changes to the reference object.
To review and recap:
-
Copy uses the dataframe’s
copy()methodtrue_copy_surveys_df = surveys_df.copy() -
A Reference is created using the
=operatorref_surveys_df = surveys_df
Okay, that’s enough of that. Let’s create a brand new clean dataframe from the original data CSV file.
surveys_df = pd.read_csv("data/surveys.csv")
Slicing Subsets of Rows and Columns in Python
We can select specific ranges of our data in both the row and column directions
using label-based indexing with the loc method. Integers may be used but
they are interpreted as a label.
# What does this do?
surveys_df.loc[0, ['species_id', 'plot_id', 'weight']]
NOTE: Labels must be found in the DataFrame or you will get a KeyError.
When using loc, integers can be used, but the integers refer to the
index label and not the position.
Subsetting Data using Criteria
We can also select a subset of our data using criteria. For example, we can select all rows that have a year value of 2002:
surveys_df[surveys_df.year == 2002]
Which produces the following output:
record_id month day year plot_id species_id sex hindfoot_length weight
33320 33321 1 12 2002 1 DM M 38 44
33321 33322 1 12 2002 1 DO M 37 58
33322 33323 1 12 2002 1 PB M 28 45
33323 33324 1 12 2002 1 AB NaN NaN NaN
33324 33325 1 12 2002 1 DO M 35 29
...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[2229 rows x 9 columns]
Or we can select all rows that do not contain the year 2002:
surveys_df[surveys_df.year != 2002]
We can define sets of criteria too:
surveys_df[(surveys_df.year >= 1980) & (surveys_df.year <= 1985)]
Python Syntax Cheat Sheet
We can use the syntax below when querying data by criteria from a DataFrame. Experiment with selecting various subsets of the “surveys” data.
- Equals:
== - Not equals:
!= - Greater than, less than:
>or< - Greater than or equal to
>= - Less than or equal to
<=
Challenge - Queries
Select a subset of rows in the
surveys_dfDataFrame that contain data from the year 1999 and that contain weight values less than or equal to 8. How many rows did you end up with? What did your neighbor get?You can use the
isincommand in Python to query a DataFrame based upon a list of values as follows:surveys_df[surveys_df['species_id'].isin([listGoesHere])]Use the
isinfunction to find all plots that contain particular species in the “surveys” DataFrame. How many records contain these values?
Experiment with other queries. Create a query that finds all rows with a weight value > or equal to 0.
The
~symbol in Python can be used to return the OPPOSITE of the selection that you specify in Python. It is equivalent to is not in. Write a query that selects all rows with sex NOT equal to ‘M’ or ‘F’ in the “surveys” data.
Challenge - Putting it all together
Create a new DataFrame that only contains observations with sex values that are not female or male. Assign each sex value in the new DataFrame to a new value of ‘x’. Determine the number of null values in the subset.
Create a new DataFrame that contains only observations that are of sex male or female and where weight values are greater than 0. Create a stacked bar plot of average weight by plot with male vs female values stacked for each plot.
Key Points
In Python, portions of data can be accessed using indices, slices, column headings, and condition-based subsetting.
Python uses 0-based indexing, in which the first element in a list, tuple or any other data structure has an index of 0.
Pandas enables common data exploration steps such as data indexing, slicing and conditional subsetting.